一、背景
在微服务化架构中,随着业务的发展,集群中部署的服务越来越多,服务之间的依赖也越来越复杂,对于后端服务的维护、问题的分析定位也越来越具有挑战性。一次用户发起的普通HTTP请求可能在集群内部涉及到数十个微服务之间的相互调用,服务之间调用的合理程度、复杂程度无法有效监控和管理。在复杂的服务之间相互依赖的情况下,我们急迫需要解决以下几个基本的问题:
- 如何快速发现问题?
- 如何判断故障影响范围?
- 如何判断链路中的性能瓶颈?
- 如何梳理服务依赖以及依赖的合理性?
- 如何分析链路性能问题以及实施容量规划?
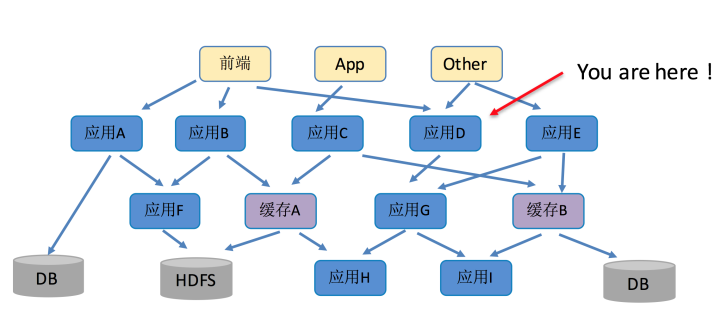
图1. 服务间调用关系
针对于以上的问题,归根到底其实是需要实现以下两个核心目标:
1、问题定位:在复杂的服务依赖下,能够快速地在日志服务中检索、过滤并准确定位当前请求错误的原因。
2、链路分析:在复杂的服务依赖下,能够方便地查看、监控、分析、统计、优化调用请求的链路情况,如方便地查看链路耗时/超时、以及层级深度情况。
这些,其实就是分布式链路跟踪技术需要解决的问题。
二、方案
分布式链路跟踪(Distributed Tracing)的概念最早是由Google提出来的,发展至今技术已经比较成熟,也是有一些技术标准可以参考,因此我们的技术方案只需按照标准实施即可。目前在Tracing技术这块比较有影响力的是两大开源技术框架:Netflix公司开源的OpenTracing和Google开源的OpenCensus。两大框架都拥有比较高的开发者群体。为形成统一的技术标准,两者经过商议成立了OpenTelemetry项目。具体可以参考:
因此,我们的Tracing技术方案以OpenTelemetry为实施标准,相关第三方开源项目:
- https://github.com/open-telemetry/opentelemetry-go
- https://github.com/open-telemetry/opentelemetry-go-contrib
我们只需要按照标准实施即可,其他第三方的框架和产品也会按照这样的标准来对接OpenTelemetry,使得开发和维护成本大大降低。
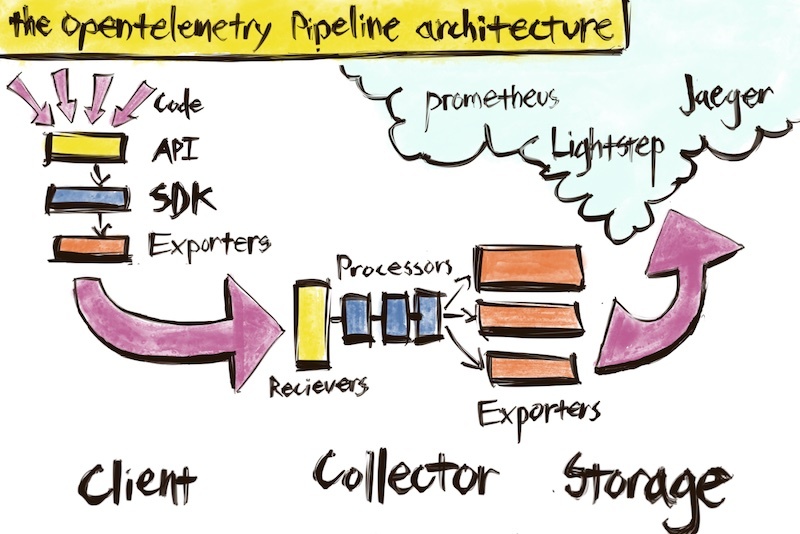
三、实施
Tracing的实施属于架构层面的事情,仅仅靠修改一两个组件是无法实现的,而是需要一整套框架联动的事情。涉及到框架支持的核心组件包括:
| No. | 核心组件 | 说明 |
|---|---|---|
| 1 | HTTP Client | HTTP客户端通过提供可选择的拦截器的形式注入。 |
| 2 | HTTP Server | HTTP服务端通过提供可选择的中间件的形式注入。 |
| 3 | GRPC Client | GRPC客户端通过提供可选择的拦截器的形式注入。支持Unary和Stream两种类型。 |
| 4 | GRPC Server | GRPC服务端通过提供可选择的拦截器的形式注入。支持Unary和Stream两种类型。 |
| 5 | Logging | 日志内容中需要注入当前请求的TraceId,以方便通过日志快速查找定位问题点。组件可以自动识别当前请求链路是否开启Tracing特性,有则自动启动自身Tracing特性,没有则忽略。 |
| 6 | ORM | 数据库的执行是很重要的链路环节,ORM组件需要将自身的执行情况投递到链路中,作为执行链路的一部分。组件可以自动识别当前请求链路是否开启Tracing特性,有则自动启动自身Tracing特性,没有则忽略。 |
| 7 | Redis | Redis/缓存管理的执行也是很重要的链路环节,Redis/缓存组件需要将自身的执行情况投递到链路中,作为执行链路的一部分。组件可以自动识别当前请求链路是否开启Tracing特性,有则自动启动自身Tracing特性,没有则忽略。 |
| 8 | Utils | 对于Tracing特性的管理需要做一定的封装,主要考虑的是可扩展性和易用性两方面。 |